Introduction
I assume all of you read part 1 of this blog and found it to
be useful. Here is the link
When Calculation trace was
presented in KScope19, one of the questions we got was whether it can tell when
the block does not exist and when we need to use @CREATEBLOCK. In this post, I
want to just address that question. For getting continuity I want to use the
model from my previous blog. It will make the example a bit artificial, but
will still show the feature working well.
Extend the Model
In this model I only had one
sparse dimension, so in order to create an example where CREATEBLOCK is needed,
I added another product P1-a5 as child of P1.

Now I want to write a calculation
script to copy the half of shipped units from P1-a1 to P1-a5 just to get an
artificial shipped percentage created for FY19. This is so that I can forecast
for FY2020 based on this. I will have to recalculate shipped percentage as well
before rerunning forecast calculation. At least that is the plan. But let us
get started with assigning shipped units of P1-a1 to P1-a5 to get started.

Running my new script
Ok, I ran my new script and I still
had my calculation trace ON. So I decided to make sure P1-a5 is being copied
correctly. I selected that cell from smart view and then click Essbase and then
calculate and run fill_P1a5, which is the calculation script I created earlier.
I was expecting to see how the number was computed in the script using the
formula and line I wrote and the numbers being copied over. But instead I found
something else.

In this case we need to make sure
the blocks are created before executing this formula. One way to do that is
walk through all the blocks in P1-a1 and then use @CREATEBLOCK to create the
corresponding P1-a5 blocks. This way P1-a5 blocks will be created only for the
cases where corresponding P1-a1 blocks exist. Ok let me try that. Let us see
how the script looks like now.
My modified script

Let me try this and see what the
tracing says and what actually happens.

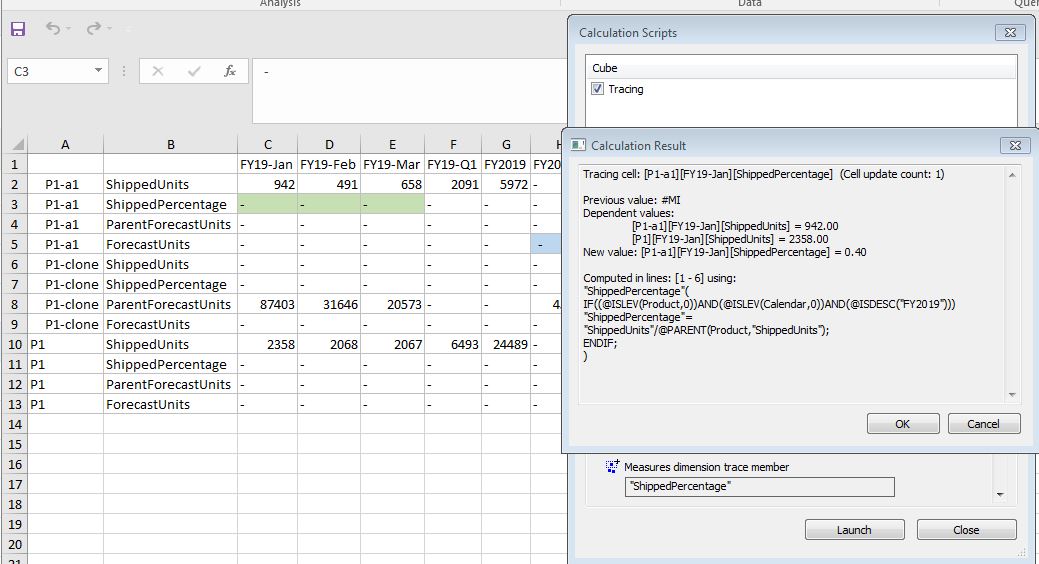
Wow! It’s telling me lot of
things. In the first pass its saying that the cell’s previous value is “None”.
Note that this is different from the new value, which is #Mi. It then shows the
line on which this block was created. Then it shows that in the next pass the
values are now being assigned using which formula. Please note one more point, it says “Cell
update count: 2” for the second pass. This is telling us that the cell was
modified twice during this calculation. You can use this sometimes to
understand performance problems or inefficiencies in your calculation scripts.
If the same cell is getting modified several times in the same script, perhaps
most of the modifications except the last one is not needed and we can use this
to understand how to get rid of them.
Also let us look at the results.
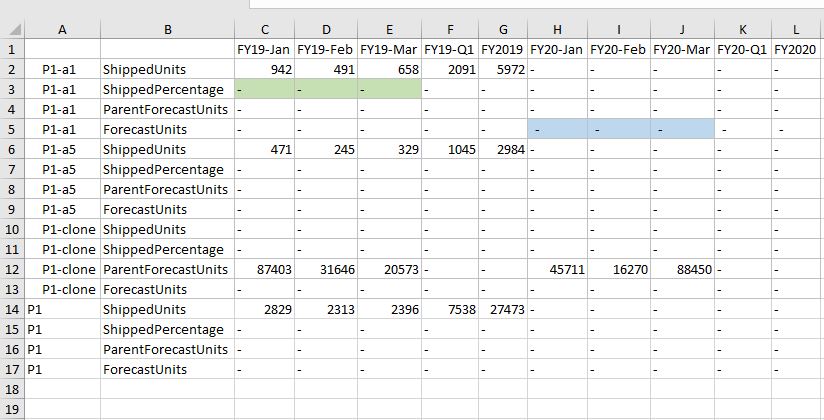
Yes, the values are now written
to P1-a5. Great!
Conclusion
CALCTRACE works well to indicate
whether the lack of block existence is the reason why certain values are not written.
It educates much more and gives lot of insights. Please keep trying and let us
know what more you like to see from this feature.